昆仑芯大规模 LLM 推理优化,实现秒级扩缩容
2026.03.25 15:32浏览量:1简介:昆仑芯大规模 LLM 推理优化,实现秒级扩缩容
本文整理自 26 年 3 月 15 日 vLLM-Kunlun Meetup 北京站活动的同名主题演讲。
在公众号回复「CUDA-like」,可以获得此次 Meetup 下半场 3 个演讲主题材料。
在实际业务运行中,大模型推理服务会面临明显的流量波动,不同时段的请求量差异很大。如果不能快速扩容,就会出现两种问题:要么峰值时服务响应慢、甚至超时,影响用户体验;要么为了应对峰值长期预留大量资源,造成资源闲置浪费。所以我们需要具备快速弹性扩缩容的能力。
但对于大模型推理而言,快速扩容存在一些现实瓶颈,从 0 到完全拉起一个大模型服务,动辄数分钟。我们以 Qwen3-235B 为例,把 521 秒冷启动耗时拆解开:69% 的时间耗在权重加载,磁盘 I/O 是最大瓶颈,传统的加载路径往往比较低效;15% 是一些编译开销;5% 是 CUDA Graph 初始化延迟。
针对前面的问题,我们对大模型冷启动的过程做出了一些优化:主要包括权重传输优化、编译缓存复用、特定场景的 CUDA Graph 延迟捕获策略,以及启动加速优化,对大模型冷启动的完整流程做了性能提升。

首先来看权重传输优化。
我们知道,模型权重是冷启动中最大的耗时项,传统方式是从磁盘加载,速度慢。我们的思路是,如果集群中已经有其他节点在运行相同的模型,我们能否直接从这些运行中的节点同步权重,而不是每次都从磁盘读取?
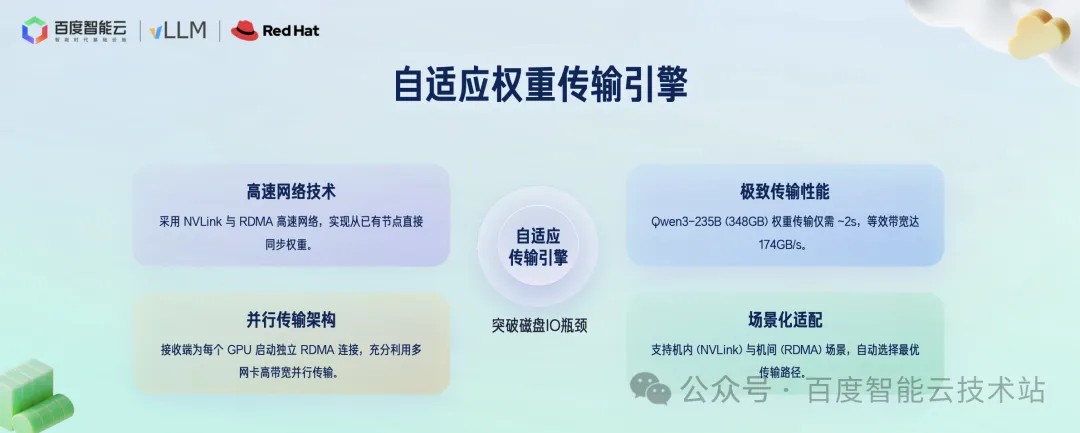
基于这个思路,我们设计了自适应权重传输引擎。它主要包含三个关键点:
第一,利用 NVLink 和 RDMA 这样的高速网络,直接在节点间传输权重,完全绕开磁盘;
第二,我们设计了并行传输架构,接收端会为每一块 GPU 都建立独立的 RDMA 连接,这样可以充分利用多网卡的带宽,实现并行传输;
第三,这个引擎能够智能地判断传输场景,如果是在同一台机器内部,就使用 NVLink,如果是在不同机器之间,就使用 RDMA,自动选择最优的传输路径。
通过这些优化,我们成功将 Qwen3-235B 模型的 348 GB 权重传输时间缩短到了约 2 秒,极大地突破了磁盘 I/O 的瓶颈。
接下来是编译缓存复用。
我们发现,在跨节点部署时,每个新节点启动都会重复大量的编译工作,这造成了大量的时间和资源浪费。我们的解决方案是,将这些编译产生的中间状态,比如 Inductor 优化缓存、DeepGEMM 算子、Triton 内核等,进行统一的缓存和管理。
当一个新节点启动时,它会首先检查是否有匹配的缓存可用,如果有,就直接通过 RDMA 高速网络从缓存节点同步过来,无需重复编译。
为了保证缓存的一致性和命中率,我们采用了一致性哈希等技术来管理缓存节点,从而实现 100% 的缓存命中率,在扩容场景下可以完全消除重复编译的开销,确保了所有推理引擎实例的一致性。

第三项优化是针对 CUDA Graph 的。
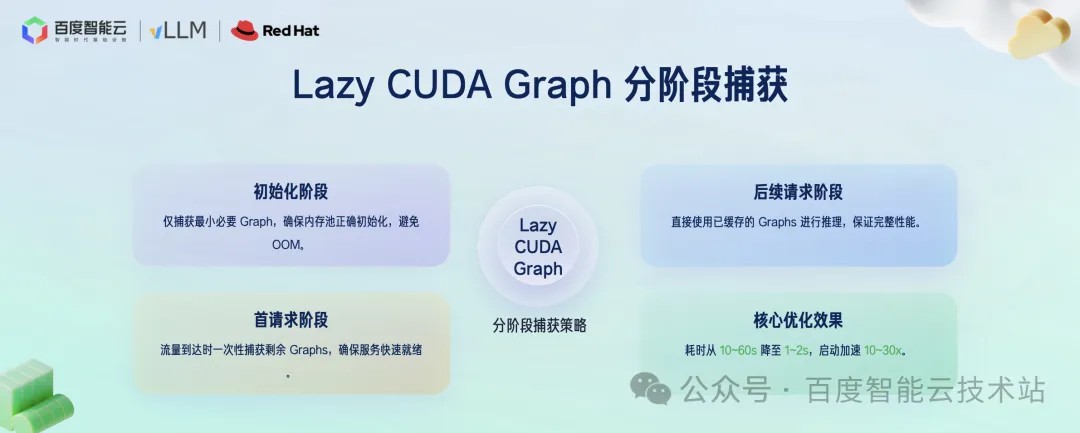
传统的 CUDA Graph 是在启动时一次性捕获所有计算图,这非常耗时,通常需要 10 到 60 秒。
我们采用了一种 Lazy CUDA Graph 的分阶段捕获策略。具体来说,在实例初始化阶段,我们只捕获最小必要的计算图,确保内存池等核心组件能够正常工作,这样可以大大减少初始化时间和显存占用。当第一个实际的推理请求到达时,我们再一次性捕获剩余的完整计算图。之后的所有请求,就可以直接复用已经缓存好的完整计算图了。
通过这种方式,我们将 CUDA Graph 的启动耗时从原来的 10–60 秒降低到了 1–2 秒,实现了 10 到 30 倍的启动加速。
接下来是守护实例预铺。
所谓守护实例,其实是在 vLLM 框架所提供的 sleep / wakeup 功能基础上做的。简单来说,我们会在系统集群中预先启动一些处于「静默」状态的模型实例。
这些实例在静默时,只保留最核心的 CUDA 上下文,而将模型权重和 KVCache 等占用大量显存的部分全部释放掉,这样可以最大限度地节省资源。
当有流量需要扩容时,我们只需要通过 RDMA 网络,从其他运行中的节点极速加载权重到这些实例中,就能快速将其唤醒为可服务状态。
这种方式下,静默实例的唤醒时间可以低至 1–2 秒,即使是像 235B 这样的大模型,唤醒时间也大约在 6 秒左右。

在进程启动层面,我们也做了优化。
Python 的多进程默认使用 Spawn 模式,这种模式在启动新进程时,需要重新加载所有的 Python 包和依赖库,这会带来数秒的额外开销。
我们的优化方法是,在创建 CUDA 上下文之前就执行 Fork 操作。这样,新的子进程可以复用父进程已经加载好的所有资源,包括 Python 解释器、已导入的库和模型配置等,从而消除重复导入的开销。

基于以上的技术优化,我们总结出了三种不同的部署模式,以适应不同的业务场景。
第一种是守护实例模式,它的特点是启动速度最快,首请求几乎没有延迟,非常适合对响应速度要求极高的核心在线业务;
第二种是 Lazy Graph 模式,它的启动时间也很短,并且不需要额外的系统资源,适合资源比较紧张或对首请求 TTFT 不敏感的场景;
第三种是正常 Graph 模式,它的优点是首请求没有延迟,也不需要预先占用资源,适合中等规模、启动频率不高的常规部署场景。
用户可以根据自己的业务需求灵活选择最合适的模式。

接下来看一下我们的实测数据。
首先是 Qwen3-235B 模型,它的原始冷启动时间是 521.01 秒。使用 Lazy Graph 模式后,启动时间缩短到了 34.45 秒。如果使用守护实例模式,唤醒时间仅需 4.91 秒,最高优化率达到了 99.06%。

我们还测试了更大的 GLM-4.5 模型。
它的权重达到了 668 GB,原始冷启动时间是 713.72 秒。
优化后,Lazy Graph 模式启动时间为 35.02 秒,守护实例唤醒时间为 8.23 秒,最高优化率也达到了 98.83%。
最后,我们将以上所有优化整合,形成了一套全场景的弹性扩缩容解决方案。
这套方案的核心优势包括:
扩容耗时降低 95%,实现了秒级响应;
348 GB 的超大权重可以在 2 秒内完成传输;
编译缓存命中率达到 100%,消除了重复开销;
整体启动速度提升了 10 到 30 倍。
这套方案深度适配 NV / 昆仑芯 P800 / P900 等硬件平台,并且兼容 vLLM、SGLang 等主流的推理引擎,可以广泛应用于各种规模的集群场景。


发表评论
登录后可评论,请前往 登录 或 注册